Deepfakes detected via reverse modeling of the vocal tract are ‘comically’ non-human

Scientists have long been researching what sorts of sounds a dinosaur made or how a person’s voice may sound based on skulls or other elements and organs that produce speech. By reversing this process and applying it to deep fakes, scientists generate models of the vocal organs that the speaker in the deepfake audio must have. And they are not of a human, as reports The Conversation.
Research by Logan Blue, PhD student in Computer and Information Science and Engineering, and Patrick Traynor, professor in the same department at the University of Florida along with research colleagues, uses the speech mechanics to reconstruct everything from vocal folds to teeth from deep fake audio, easily discovering the tell.
Their technique measures the acoustic and fluid dynamic differences in voice samples from humans and those generated synthetically. The models, even as line drawings, clearly show the difference, with the synthetic voice revealing that it has not been made in the same way as a human voice, that it has not come from a human body.
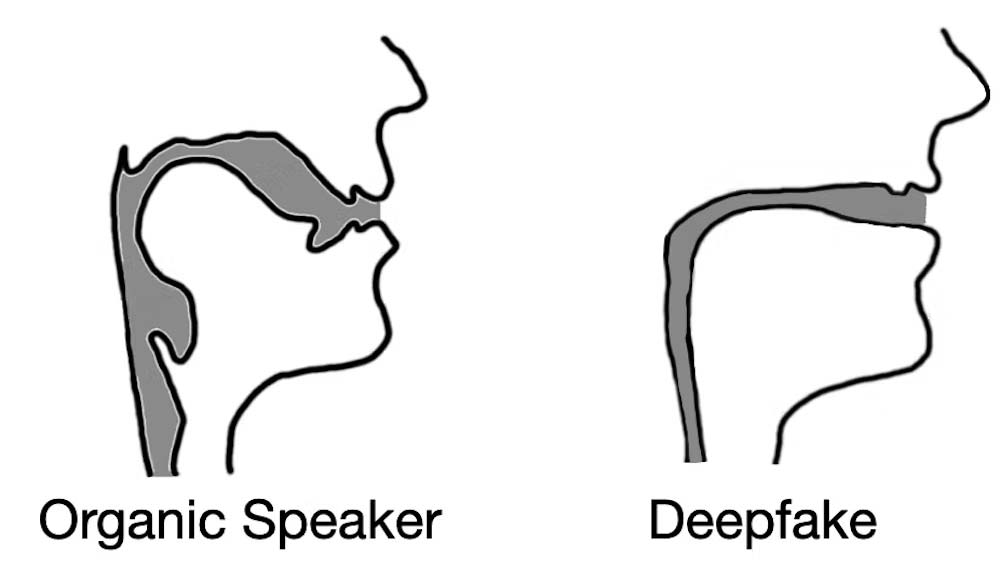
Representation of the differences between real and fake vocal tracts. Credit: Logan Blue et al., CC BY-ND
“When extracting vocal tract estimations from deepfake audio, we found that the estimations were often comically incorrect,” write the researchers in The Conversation. “For instance, it was common for deepfake audio to result in vocal tracts with the same relative diameter and consistency as a drinking straw, in contrast to human vocal tracts, which are much wider and more variable in shape.”
Deep fakes often succeed via social engineering, rather than fooling biometric identity checks. Audio is easier to pull off than video, but may now also be easier to detect. Biometric precision verification could be another tool to detect attempts, Russia’s Sber bank is patenting a method for detecting the circulation of blood below a speaker’s skin.
Paravision has recently received funding from an unnamed partner of the Five Eyes alliance to detect deepfake videos.
Article Topics
biometrics | biometrics research | deepfakes | synthetic data | synthetic voice | voice biometrics

Comments